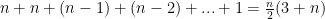Recently I stumbled upon an issue of stuck thread. The thread seemed to be stuck with stack trace something like the one below:-
java.util.SubList$1.nextIndex(AbstractList.java:713)
java.util.SubList$1.nextIndex(AbstractList.java:713) ...Repeated 100s of times...
java.util.SubList$1.nextIndex(AbstractList.java:713)
java.util.SubList$1.hasNext(AbstractList.java:691)
java.util.SubList$1.next(AbstractList.java:695)
java.util.SubList$1.next(AbstractList.java:696) ...Again repeated 100s of times...
java.util.SubList$1.next(AbstractList.java:696)
java.util.AbstractList.hashCode(AbstractList.java:526)
java.util.Collections$UnmodifiableList.hashCode(Collections.java:1152)
org.apache.myfaces.trinidad.util.CollectionUtils$DelegatingCollection.hashCode(CollectionUtils.java:603) ...
My initial reaction was – huh?! Well googling revealed a blog post related to this issue – Java subList Gotcha. Ya I too have used the same title, as it seems to be the most appropriate one.
The gotcha
The author of that blog post explained, that contrary to what you may expect but subList() does not return a new instance of the list but it returns a ‘view’ of it. What this means is that subList() will return an instance of class SubList or RandomAccessSubList, based on if the original list doesn’t or does implement RandomAccess interface, and they contain a reference to the original list. Note that both these classes are actually inner classes of AbstractList. For most part you can simply disregard this piece of information but in some cases it has some serious consequences. Check out the code below.
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class Sublist {
public static void main(String[] args) {
weirdList(new LinkedList<Integer>()); // Will result in generation of
// SubList
weirdList(new ArrayList<Integer>()); // Will result in generation of
// RandomAccessSubList
}
static void weirdList(List<Integer> list) {
List<Integer> alist = list, blist = list;
list.clear();
for (int i = 1; i <= 5000; i++) {
list.add(i);
}
for (int i = 1; i <= 500; i++) {
alist = alist.subList(1, alist.size()); // Wrong
}
for (int i = 1; i <= 500; i++) {
blist = new ArrayList<Integer>(blist.subList(1, blist.size())); // Correct
}
long startTime = System.nanoTime();
System.out.println(alist.hashCode());
long endTime = System.nanoTime();
System.out.println("Total time taken for hasCode() = " + (endTime - startTime) / 1000000.0 + "ms");
startTime = System.nanoTime();
System.out.println(blist.hashCode());
endTime = System.nanoTime();
System.out.println("It should take = " + (endTime - startTime) / 1000000.0 + "ms\n");
}
}
If you run the above code then you will notice that alist.hasCode() will typically take 4s more than blist.hasCode(). Even though they both pointed to the very same list!
How the hell hashCode() end up triggering this mess?
Before I continue, I would urge that you take a look at how AbstractList.hashCode() is implemented. This will help you to understand as to as how did the code end up calling next() in SubList. See below.
public int hashCode() {
int hashCode = 1;
for (E e : this)
hashCode = 31*hashCode + (e==null ? 0 : e.hashCode());
return hashCode;
}
From above it seems that a list’s has-code is calculated based on the hash-codes of all its elements. The for-each loop actually gets a reference of the iterator of the list by calling the list’s iterator() method. Then it calls the next() method over the iterator to get the next element if hasNext() returned true. Now lets get back to the first Java code listing. The whole reason for bad performance of alist is due to the following line:-
alist = alist.subList(1, alist.size());
Yes this simple benign looking line. Let’s understand its reason.
Here comes the innocent devil
I already mentioned that subList() returns instance of SubList or RandomAcessSubbList. Now let’s see that code snippet from AbstractList.
public List<E> subList(int fromIndex, int toIndex) {
return (this instanceof RandomAccess ?
new RandomAccessSubList<E>(this, fromIndex, toIndex)
: new SubList<E>(this, fromIndex, toIndex));
}
Well let’s take the case where alist refers to an instance of LinkedList, and since LinkedList is does not implement RandomAccess so alist.subList() will return a new instance of SubList. This instance of SubList will point to the original list which actually has the elements. So, lets represent that visually as below:-
SubList-1->OriginalList After executing the code alist = alist.subList() for the first time, the situation will be like below:-
(alist = SubList-1)->OriginalList After executing that code the second time, it becomes:-
(alist = SubList-2)->SubList-1->OriginalList So after n-iterations it will be:-
(alist = SubList-n)->SubList-(n-1)->…->SubList-1->OriginalList
Ok, now you must be wondering, what exactly does the above represent? Well then let’s see the code of Sublist.iterator(int).
public ListIterator<E> listIterator(final int index) {
checkForComodification();
rangeCheckForAdd(index);
return new ListIterator<E>() {
private final ListIterator<E> i = l.listIterator(index+offset);
public boolean hasNext() { return nextIndex() < size; }
public E next() {
if (hasNext())
return i.next();
else
throw new NoSuchElementException();
}
public boolean hasPrevious() { return previousIndex() >= 0; }
public E previous() {
if (hasPrevious())
return i.previous();
else
throw new NoSuchElementException();
}
public int nextIndex() { return i.nextIndex() - offset; }
public int previousIndex() { return i.previousIndex() - offset; }
public void remove() {
i.remove();
SubList.this.modCount = l.modCount; size--;
}
public void set(E e) { i.set(e); }
public void add(E e) {
i.add(e);
SubList.this.modCount = l.modCount; size++;
}
};
}
When hashCode() is called on alist, it actually calls hashCode() on the instance of SubList-n. So to get the iterator hasCode() actually invokes SubList.iterator() which in-turn invokes SubList.listIterator() and which finally invokes SubList.listIterator(int) (whose code is shown above). Note that this method returns an anonymous instance of ListIterator. Now take a close look at the stack trace (right at the top of this post). Did you notice the $1 in the stack trace? This means the method is stuck in next() of the anonymous ListIterator. So, the hashCode() code first calls SubList$1.hasNext() which in-turn invokes its own nextIndex() which further invokes the nextIndex() of the iterator of the list it points. So, in case of SubList-n this will be SubList-(n-1). This call will go on and on till the code reaches the original list. If hasNext returned true then next the hashCode() code will invoke SubList$1.next(). Which will invoke its own hasNext() and that will again go through all the steps mentioned above, and when it returns true then it will invoke next() on the iterator of the list it references. So for each iterations in hasCode() of SubList-n the code has to recursively go down the full the depth almost 3-times^1!
Finding the maxima. Err… involves some simple maths
Try to run the Java code listed at the top of the post and try changing 5000 to 1000. Then try running that program multiple times, each time increasing the values of the rest two for loops in multiples of 100. You will notice the peak performance penalty comes at iteration of 700 for 1000 elements. You might be surprised at first but think about this. When you increase the iterations so much that SubList-n has zero elements then there will be no performance penalty. This is a limiting case. So there must be some peak point between the two extremes, i.e. when the SubList-n directly refers to the original list (when n=1) but it contains n-1 elements, and the other extreme being when SubList-n has only zero elements. So, we begin. After 1st iteration the number of elements in alist is n-1 and has 1 SubList to reach the original list. After 2nd iteration the number of elements in alist is n-2 and has 2 SubLists to reach the original list. … After 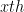 iteration the number of elements in
iteration the number of elements in alist is  and has
and has  SubLists to reach the original list.
SubLists to reach the original list.
$$ \begin{align} O(n) &= x (n-x)\\ &= xn – x^2 \end{align} $$
Now to find the maxima,
$$ \begin{align} \frac{dO(n)}{dx} = 0\\ &\Rightarrow \frac{d(xn – x^2)}{dx} = 0\\ &\Rightarrow \frac{ndx}{dx} – \frac{d(x^2)}{dx} = 0\\ &\Rightarrow n – 2x = 0\\ &\Rightarrow n = 2x\\ &\Rightarrow x = \frac{n}{2} \end{align} $$
So from above it is clear that the maxima is reached when number of partitioning (iterations with alist=alist.subList()) is half the total amount of data. Practical experiments show that the actual maxima is slightly shifted further away from the half point.
Summary. Phew! Finally!
If you use subList wrongly then a time will come when dealing with large data your thread will appear to be stuck. In reality the code is not really hung but is doing a hell lot of iterations. In fact if you take the snapshot of your stuck thread then you will see the stack is growing, if not then at least note the position of the line java.util.SubList$1.hasNext(AbstractList.java:691). The position of this line would be changing rapidly in the stack.
^1 More accurately