`AG_BACKQUOTE_TURN_ON`
If you are here then most probably, like me you too want to migrate from Apache to Nginx. Well I have already migrated and I am loving it! You can get a quick recap of Apache vs Nginx comparison here. Via this blog post I will share and explain my Nginx conf, in the hope that this can prove helpful for you. I have assumed that you have Nginx and Php-FPM installed. You can read how to install Ngnix from here – http://goo.gl/tq6vT. I installed it from its source. You can install PHP-FPM as per the guide at – http://goo.gl/Fx9hJ. My repo had PHP-FPM so I was saved from this trouble.
The net is littered with loads of blog posts on this topic, but most of them are either out of date or make contradictory suggestions. I have scoured the net and cooked up my own Nginx config based on many helpful blog posts on them. My config has been progressively tweaked as per my needs. I now feel that it is good enough to be shared.
To see if my Nginx config suites your needs, you first need to understand my use case. I have four domains hosted on the same server – applegrew.com, cink.applegrew.com, fb.applegrew.com and this blog.
- applegrew.com – This serves some static HTML, few XMLs and dynamic web pages (PHP).
- cink.applegrew.com – This is my Chrome Experiment site and has no dynamic web pages, only static files like HTMLs, images, text files, etc.
- fb.applegrew.com – I added this one recently to host my Facebook Apps. So, naturally this has dynamic web pages, coded in PHP. Since, FB has mandated that from 1 Oct, 2011, all FB Apps must be accessible via HTTPS, so, this domain is configured to be accessible via both HTTP and HTTPS. The Nginx config for this takes care of setting the PHP parameter `$_SERVER[‘HTTPS’]` when HTTPS is used.
- blog.applegrew.com– Configuring Nginx for this blog was no easy task. This blog is powered by WordPress. If you too have a WordPress blog then you MUST install the following WP plugins for performance. The Nginx config that I have shared assumes that these plugins are installed and takes full advantage of it.
Must have WordPress plugins:-
- WP Super Cache– Excellent plugin which generates static HTML files for your blog. Nobody updates their blog every minute. It’s not a Twitter. So, why generate that same page again and again for every user who visits you blog? The solution is to cache the generate page. Later when any user visits your blog then that user will be served the cached page. This saves a ton of overhead. Particularly when you are using Nginx, since, we run PHP and Nginx processes separately. So we can configure Nginx to serve the generated file, if present, and completely bypass PHP. This plugin is smart enough to refresh the cache when you make a new post or update it.
Tip: Install this plugin after you have finalized your sites design, else you will have to manually clean the cache to make the site changes available.
- WP Minify– This plugin strips out all the JS and CSS links from your blog and then combines them generate a unified CSS and JS. The result is cut down on the number of requests to your server for additional CSS and JS files. This plugin also minifies the combined CSS and JS files, which produces a much smaller file.
Tip: If you install a new plugin after you install this one, and if that is not working, then try clearing the cache of this plugin. Since, it is possible that the new plugin will try to put some new CSS or JS which might get stripped out but not cached in the combined file.
- WP Super Cache– Excellent plugin which generates static HTML files for your blog. Nobody updates their blog every minute. It’s not a Twitter. So, why generate that same page again and again for every user who visits you blog? The solution is to cache the generate page. Later when any user visits your blog then that user will be served the cached page. This saves a ton of overhead. Particularly when you are using Nginx, since, we run PHP and Nginx processes separately. So we can configure Nginx to serve the generated file, if present, and completely bypass PHP. This plugin is smart enough to refresh the cache when you make a new post or update it.
Now its time for the configs.
nginx.conf
[code lang=”cink”]
user apache apache; #The uid and gid of the nginx process
worker_processes 4; #Number of worker processes that needs to be created.
error_log /var/log/error-n.log;
pid /usr/local/nginx/logs/nginx.pid;
events {
worker_connections 1000;
}
http {
include mime.types; #Includes a config file which is available with ngix’s default installation.
index index.html index.htm index.php index.shtml;
log_format main ‘$remote_addr – $remote_user [$time_local] "$request" ‘
‘$status $body_bytes_sent "$http_referer" ‘
‘"$http_user_agent" "$http_x_forwarded_for"’;
sendfile on;
keepalive_timeout 5;
gzip on;
# Sets the default type to text/html so that gzipped content is served
# as html, instead of raw uninterpreted data.
#default_type text/html;
server {#If someone tries to access the url http://applegrew.com/xxx then
#this will redirect him to http://www.applegrew.com/xxx.
server_name applegrew.com;
rewrite ^ http://www.applegrew.com$request_uri? permanent;
}
server {#The config for www.applegrew.com
server_name www.applegrew.com;
access_log /var/www/applegrew.com/access-n.log main; #Where access log will be written for this domain.
error_log /var/www/applegrew.com/error-n.log;
root /var/www/applegrew.com/html; #The document root for this domain.
location ~ /admin/ { deny all; } #Denies access to some www.applegrew.com/admin/ url
location ~ /private/ { deny all; }
include cacheCommon.conf; #This caches common static files. This config is given later in this post.
include drop.conf; #This config is given later in this post.
include php.conf; #Configures PHP access for this domain. This config is given later in this post.
include err.conf; #Some common custom error messages I show. This config is given later in this post.
}
server {#Config to serve HTTP traffic.
server_name fb.applegrew.com;
access_log /var/www/fb.applegrew.com/access.log main;
error_log /var/www/fb.applegrew.com/error.log;
root /var/www/fb.applegrew.com/html;
include cacheCommon.conf;
include php.conf;
include drop.conf;
include err.conf;
}
server {//Config to serve HTTPS traffic.
listen 443;
server_name fb.applegrew.com;
ssl on;
ssl_certificate /var/ssl/fb.applegrew.com.crt; #See http://goo.gl/mvHo7 to know how to create crt file.
ssl_certificate_key /var/ssl/fb_applegrew_com.key;
access_log /var/www/fb.applegrew.com/access.log main;
error_log /var/www/fb.applegrew.com/error.log;
root /var/www/fb.applegrew.com/html;
include cacheCommon.conf;
include phpssl.conf; #Notice the difference. This is not php.conf. This config will be provided later in this post.
include drop.conf;
include err.conf;
}
server {
server_name blog.applegrew.com;
access_log /var/www/blog.applegrew.com/access-n.log main;
error_log /var/www/blog.applegrew.com/error-n.log;
root /var/www/blog.applegrew.com/html;
#If tgz file mathcing the request already exists then that will be sent, skipping on the fly compression by nginx.
gzip_static on;
location / {
# does the requested file exist exactly as it is? if yes, serve it and stop here
if (-f $request_filename) { break; }
# sets some variables to help test for the existence of a cached copy of the request
set $supercache_file ”;
set $supercache_uri $request_uri;
# IF the request is a post, has a query attached, or a cookie
# then don’t serve the cache (ie: users logged in, or posting comments)
if ($request_method = POST) { set $supercache_uri ”; }
if ($query_string) { set $supercache_uri ”; }
if ($http_cookie ~* "comment_author_|wordpress|wp-postpass_" ) {
set $supercache_uri ”;
}
# if the supercache_uri variable hasn’t been blanked by this point, attempt
# to set the name of the destination to the possible cache file
if ($supercache_uri ~ ^(.+)$) {
set $supercache_file /wp-content/cache/supercache/$http_host/$1index.html;
}
# If a cache file of that name exists, serve it directly
if (-f $document_root$supercache_file) { rewrite ^ $supercache_file break; }
# Otherwise send the request back to index.php for further processing
if (!-e $request_filename) { rewrite . /index.php last; }
#try_files $uri $uri/ /index.php;
}
location ~ /wp-config\.php { deny all; }
location ~ /wp-content/bte-wb/.*\..* { deny all; }
include cacheCommon.conf;
include drop.conf;
include php.conf;
include err.conf;
#Let wordpress show its own error pages.
fastcgi_intercept_errors off;
}
server {
server_name cink.applegrew.com;
access_log /var/www/cink.applegrew.com/access-n.log main;
error_log /var/www/cink.applegrew.com/error-n.log;
root /var/www/cink.applegrew.com/html;
include cacheCommon.conf;
include drop.conf;
include err.conf;
}
server {#If none the above matched then maybe the url was accessed, (say) via the IP directly. We then show applegrew.com.
listen 80 default;
server_name _;
access_log /var/www/applegrew.com/access.log-n main;
server_name_in_redirect off;
rewrite ^ http://www.applegrew.com$request_uri? permanent;
include err.conf;
}
}
[/code]
cacheCommon.conf
[code lang=”cink”]
#Asks browsers to cache files with extension ico, css, gif, jpg, jpeg, png, txt and xml.
location ~* \.(?:ico|css|js|gif|jpe?g|png|txt|xml)$ {
# Some basic cache-control for static files to be sent to the browser
expires max;
add_header Pragma public;
add_header Cache-Control "public, must-revalidate, proxy-revalidate";
}
[/code]
drop.conf
[code lang=”cink”]
location = /favicon.ico { access_log off; log_not_found off; } #Don’t log this.
location ~ /\. { access_log off; log_not_found off; deny all; } #Block . (dot) files access
#Don’t log and deny access to files which end with ~, as these are usually backup files.
location ~ ~$ { access_log off; log_not_found off; deny all; }
[/code]
err.conf
[code lang=”cink”]
error_page 500 502 503 504 /50x.html;
error_page 403 404 /404.html; # Yes for 403 too we show 404 error, just to mislead.
location = /50x.html {
root /home/webadmin/err/;
}
location = /404.html {
root /home/webadmin/err/;
}
[/code]
php.conf
[code lang=”cink”]
location ~ \.php { #All requests that end with .php are directed to PHP process.
include phpparams.conf; #This file is described later in this post.
}
[/code]
phpssl.conf
[code lang=”cink”]
location ~ \.php {#This the same as php.conf but adds few ssl specific configs.
fastcgi_param HTTPS on; #This sets $_SERVER[‘HTTPS’] to ‘on’.
fastcgi_param SSL_PROTOCOL $ssl_protocol; #This sets the $_SERVER[‘SSL_PROTOCOL’].
fastcgi_param SSL_CIPHER $ssl_cipher; #This sets the $_SERVER[‘SSL_CIPHER’].
fastcgi_param SSL_SESSION_ID $ssl_session_id; #This sets the $_SERVER[‘SSL_SESSION_ID’].
fastcgi_param SSL_CLIENT_VERIFY $ssl_client_verify; #This sets the $_SERVER[‘SSL_CLIENT_VERIFY’].
include phpparams.conf;
}
[/code]
We need to set the `$_SESSION` ourselves since unlike mod_php (in Apache), Php-Fpm is not embedded in Nginx and it doesn’t have these information available to it unless we set it. The above config doesn’t set all the flags a script might expect, but the usual ones. If need to set some more then go to Nginx HttpSslModule’s Built-in variables section.
phpparams.conf
[code lang=”cink”]
#PHP FastCGI
fastcgi_param QUERY_STRING $query_string;
fastcgi_param REQUEST_METHOD $request_method;
fastcgi_param CONTENT_TYPE $content_type;
fastcgi_param CONTENT_LENGTH $content_length;
fastcgi_param SCRIPT_NAME $fastcgi_script_name;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_param REQUEST_URI $request_uri;
fastcgi_param DOCUMENT_URI $document_uri;
fastcgi_param DOCUMENT_ROOT $document_root;
fastcgi_param SERVER_PROTOCOL $server_protocol;
fastcgi_param GATEWAY_INTERFACE CGI/1.1;
fastcgi_param SERVER_SOFTWARE nginx;
fastcgi_param REMOTE_ADDR $remote_addr;
fastcgi_param REMOTE_PORT $remote_port;
fastcgi_param SERVER_ADDR $server_addr;
fastcgi_param SERVER_PORT $server_port;
fastcgi_param SERVER_NAME $server_name;
fastcgi_connect_timeout 60;
fastcgi_send_timeout 180;
fastcgi_read_timeout 180;
fastcgi_buffer_size 128k;
fastcgi_buffers 4 256k;
fastcgi_busy_buffers_size 256k;
fastcgi_temp_file_write_size 256k;
fastcgi_pass unix:/usr/local/nginx/logs/php5-fpm.sock; #I have configured both Php-Fpm and Nginx to communicate via file sockets.
[/code]
/etc/php-fpm.conf
[code]
include=/etc/php-fpm.d/*.conf
pid = /var/run/php-fpm/php-fpm.pid
error_log = /var/log/php-fpm/error.log
log_level = error
[/code]
/etc/php-fpm.d/www.conf
[code]
[www]
listen = /usr/local/nginx/logs/php5-fpm.sock
listen.allowed_clients = 127.0.0.1
user = apache
group = apache
pm = dynamic
pm.max_children = 6; #This can be increased on 512MB RAM. For 256MB you ca use 2.
pm.start_servers = 3; #This can be increased. For 256MB you can use 1.
pm.min_spare_servers = 3; #This can be increased. For 256MB you can use 1.
pm.max_spare_servers = 5; #This can be increased. For 256MB you can use 1.
pm.max_requests = 500
slowlog = /var/log/php-fpm/www-slow.log
php_admin_value[error_log] = /var/log/php-fpm/www-error.log #All PHP errors will go into this.
php_admin_flag[log_errors] = on
[/code]
Note: The settings above are indicative. You need to experiment with different settings on your system. I have a MySql DB too running on the same system. In my case the minimal settings for 256MB RAM too cause problem. The PHP process used to choke after 4-5 days of running. So, finally I was forced to increase server RAM to 512MB.
/etc/init.d/nginxd
I wrote this shell script to start stop nginx as a service on my CentOS server.
[code lang=”bash”]
#!/bin/bash
# chkconfig: 235 85 15
# description: The Nginx Server is an efficient and extensible \
# server implementing the current HTTP standards.
cmd=/usr/local/nginx/sbin/nginx #Change this to match your Nginx installation path.
start() {
pgrep ‘nginx$’ > /dev/null
if (( $? != 0 ))
then
echo ‘Staring nginx’
$cmd
RETVAL=$?
if (( $RETVAL == 0 ))
then
echo ‘Started successfully’
fi
else
echo ‘Nginx already running’
RETVAL=0
fi
}
RETVAL=0
case "$1" in
start)
start
;;
stop)
echo ‘Shutting down Nginx quickly’
$cmd -s stop
RETVAL=$?
;;
quit)
echo ‘Gracefully shutting down Nginx’
$cmd -s quit
RETVAL=$?
;;
restart)
echo ‘Stopping Nginx’
$cmd -s stop
start
;;
reload)
echo ‘Reloading cofig’
$cmd -s reload
RETVAL=$?
;;
reopen)
echo ‘Reopening log files’
$cmd -s reopen
RETVAL=$?
;;
help)
$cmd -?
RETVAL=$?
;;
test)
echo ‘Test config’
$cmd -t
RETVAL=$?
;;
*)
echo $"Usage: nginx {start|stop|quit|restart|reload|reopen|help|test}"
echo "stop – quick shutdown"
echo "quit – graceful shutdown"
echo "reload – close workers, load config, start new workers"
echo "reopen – reopen log files"
echo "test – only tests the config"
RETVAL=3
esac
exit $RETVAL
[/code]
You can install the above by copying the nginxd file to /etc/init.d then run
`sudo /sbin/chkconfig nginxd –add`
`sudo /sbin/chkconfig nginxd on`
You can the give commands to the script by
`sudo /sbin/service nginxd command here`
Well, I hope this post been helpful.

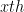 iteration the number of elements in
iteration the number of elements in  and has
and has  SubLists to reach the original list.
SubLists to reach the original list.